Ning Ding 丁宁
Assistant Professor @ Tsinghua
Bio
I am a tenure-track Assistant Professor at the Department of Electronic Engineering, Tsinghua University. Previously, I was a postdoc researcher in the same department, advised by Prof. Bowen Zhou. I received Ph.D. at the Department of Computer Science and Technology, Tsinghua Univeristy in 2023, advised by Prof. Hai-Tao Zheng and also co-advised by Prof. Zhiyuan Liu.
Research
My research spans the areas of natural language processing and machine learning. Currently I am working on theories and scalable methods for developing reasoning intelligence that balances exploration and learning. I am also interested in how specialized general reasoners can facilitate scientific innovations.
Our group is looking for self-motivated Ph.D. students, Postdocs, and interns. Research topics include theories and scalable methods for large language, reasoning, and embodied models.
If you are interested, please drop an email to dingning AT mail.tsinghua.edu.cn with your CV.
Selected Papers
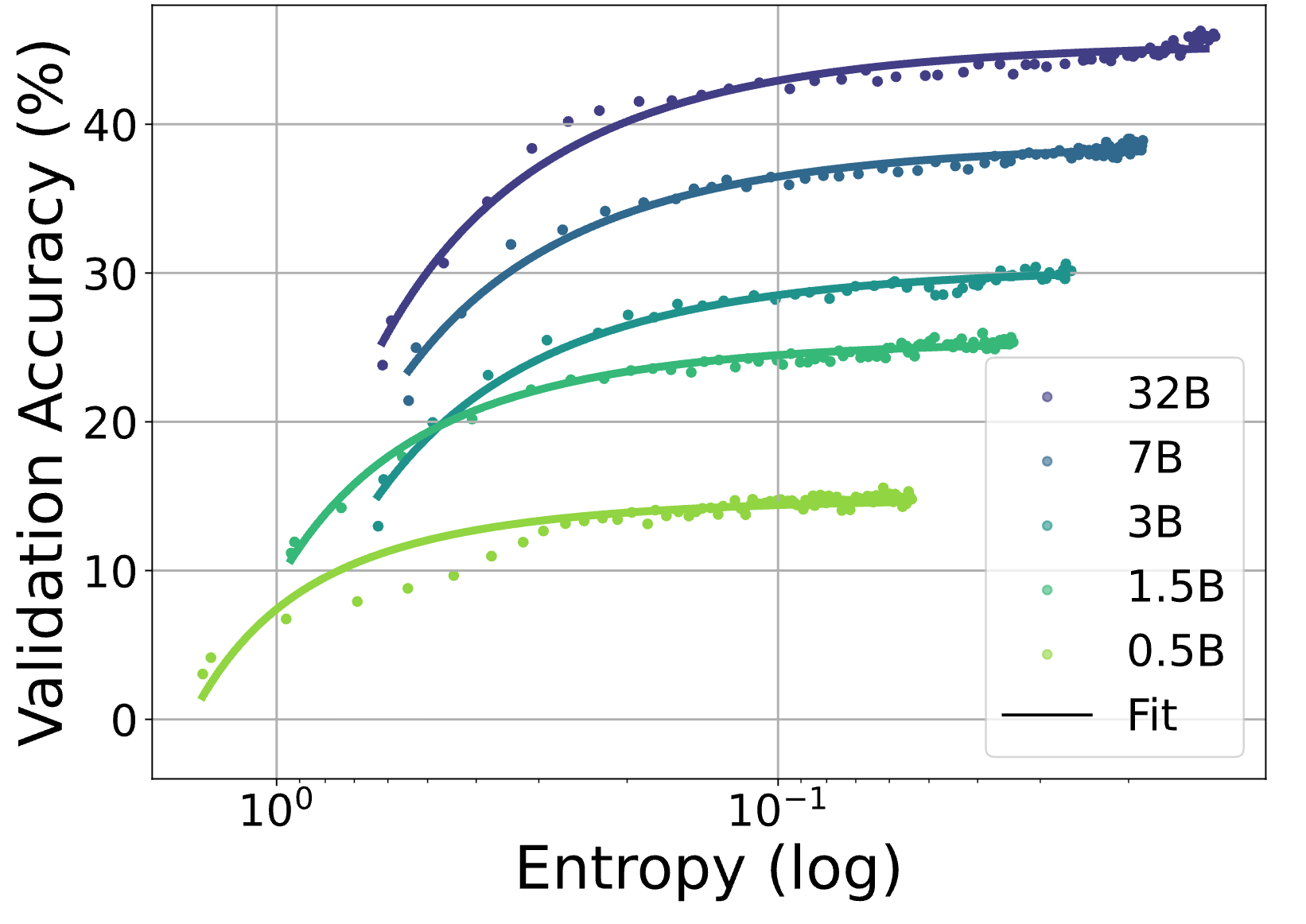 The Entropy Mechanism of Reinforcement Learning for Reasoning Language ModelsGanqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, +7 more authors , Yu Cheng, Bowen Zhou, and Ning Ding Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning DingPreprint
The Entropy Mechanism of Reinforcement Learning for Reasoning Language ModelsGanqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, +7 more authors , Yu Cheng, Bowen Zhou, and Ning Ding Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning DingPreprintThis paper aims to overcome a major obstacle in scaling RL for reasoning with LLMs, namely the collapse of policy entropy. Such phenomenon is consistently observed across vast RL runs without entropy intervention, where the policy entropy dropped sharply at the early training stage, this diminished exploratory ability is always accompanied with the saturation of policy performance. In practice, we establish a transformation equation R=-a*e^H+b between entropy H and downstream performance R. This empirical law strongly indicates that, the policy performance is traded from policy entropy, thus bottlenecked by its exhaustion, and the ceiling is fully predictable H=0, R=-a+b. Our finding necessitates entropy management for continuous exploration toward scaling compute for RL. To this end, we investigate entropy dynamics both theoretically and empirically. Our derivation highlights that, the change in policy entropy is driven by the covariance between action probability and the change in logits, which is proportional to its advantage when using Policy Gradient-like algorithms. Empirical study shows that, the values of covariance term and entropy differences matched exactly, supporting the theoretical conclusion. Moreover, the covariance term stays mostly positive throughout training, further explaining why policy entropy would decrease monotonically. Through understanding the mechanism behind entropy dynamics, we motivate to control entropy by restricting the update of high-covariance tokens. Specifically, we propose two simple yet effective techniques, namely Clip-Cov and KL-Cov, which clip and apply KL penalty to tokens with high covariances respectively. Experiments show that these methods encourage exploration, thus helping policy escape entropy collapse and achieve better downstream performance.
@article{preprint:entropy, title = {The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models}, bibtex_show = {true}, journal = {Preprint}, preview = {entropy2.png}, selected = {true}, author = {Cui, Ganqu and Zhang, Yuchen and Chen, Jiacheng and Yuan, Lifan and Wang, Zhi and Zuo, Yuxin and Li, Haozhan and Fan, Yuchen and Chen, Huayu and Chen, Weize and Liu, Zhiyuan and Peng, Hao and Bai, Lei and Ouyang, Wanli and Cheng, Yu and Zhou, Bowen and Ding, Ning*}, code = {https://github.com/PRIME-RL/Entropy-Mechanism-of-RL}, pdf = {https://arxiv.org/abs/2505.22617}, year = {2025} }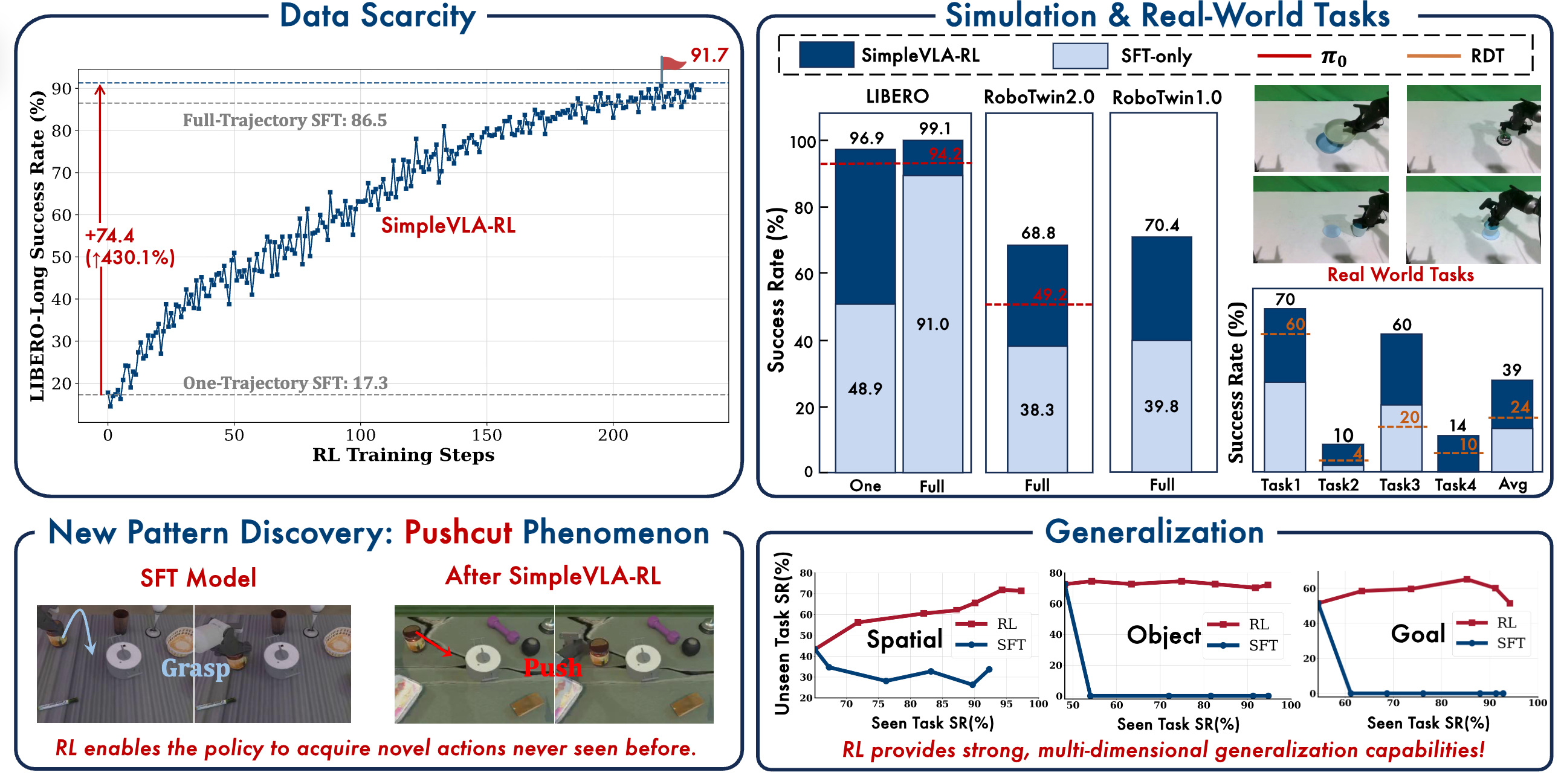 SimpleVLA-RL: Scaling VLA Training via Reinforcement LearningHaozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Xuekai Zhu Kaiyan Zhang, Yuchen Zhang, +8 more authors , Yao Mu, Bowen Zhou, and Ning Ding Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Xuekai Zhu Kaiyan Zhang, Yuchen Zhang, Ganqu Cui Tianxing Chen, Dehui Wang, Dingxiang Luo, Yuchen Fan, Youbang Sun, Jiangmiao Pang Jia Zeng, Shanghang Zhang, Yu Wang, Yao Mu, Bowen Zhou, and Ning DingPreprint
SimpleVLA-RL: Scaling VLA Training via Reinforcement LearningHaozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Xuekai Zhu Kaiyan Zhang, Yuchen Zhang, +8 more authors , Yao Mu, Bowen Zhou, and Ning Ding Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Xuekai Zhu Kaiyan Zhang, Yuchen Zhang, Ganqu Cui Tianxing Chen, Dehui Wang, Dingxiang Luo, Yuchen Fan, Youbang Sun, Jiangmiao Pang Jia Zeng, Shanghang Zhang, Yu Wang, Yao Mu, Bowen Zhou, and Ning DingPreprintVision-Language-Action (VLA) models have recently emerged as a powerful paradigm for robotic manipulation. Despite substantial progress enabled by large-scale pretraining and supervised fine-tuning (SFT), these models face two fundamental challenges: (i) the scarcity and high cost of large-scale human-operated robotic trajectories required for SFT scaling, and (ii) limited generalization to tasks involving distribution shift. Recent breakthroughs in Large Reasoning Models (LRMs) demonstrate that reinforcement learning (RL) can dramatically enhance step-by-step reasoning capabilities, raising a natural question: Can RL similarly improve the long-horizon step-by-step action planning of VLA? In this work, we introduce SimpleVLA-RL, an efficient RL framework tailored for VLA models. Building upon veRL, we introduce VLA-specific trajectory sampling, scalable parallelization, multi-environment rendering, and optimized loss computation. When applied to OpenVLA-OFT, SimpleVLA-RL achieves SoTA performance on LIBERO and even outperforms π0 on RoboTwin 1.0&2.0 with the exploration-enhancing strategies we introduce. SimpleVLA-RL not only reduces dependence on large-scale data and enables robust generalization, but also remarkably surpasses SFT in real-world tasks. Moreover, we identify a novel phenomenon “pushcut” during RL training, wherein the policy discovers previously unseen patterns beyond those seen in the previous training process.
@article{preprint:simplevla, title = {SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning}, bibtex_show = {true}, journal = {Preprint}, preview = {simplevla.png}, selected = {true}, author = {Li, Haozhan and Zuo, Yuxin and Yu, Jiale and Zhang, Yuhao and Yang, Zhaohui and Kaiyan Zhang, Xuekai Zhu and Zhang, Yuchen and Tianxing Chen, Ganqu Cui and Wang, Dehui and Luo, Dingxiang and Fan, Yuchen and Sun, Youbang and Jia Zeng, Jiangmiao Pang and Zhang, Shanghang and Wang, Yu and Mu, Yao and Zhou, Bowen and Ding, Ning*}, code = {https://github.com/PRIME-RL/SimpleVLA-RL}, pdf = {https://arxiv.org/abs/2509.09674}, year = {2025} }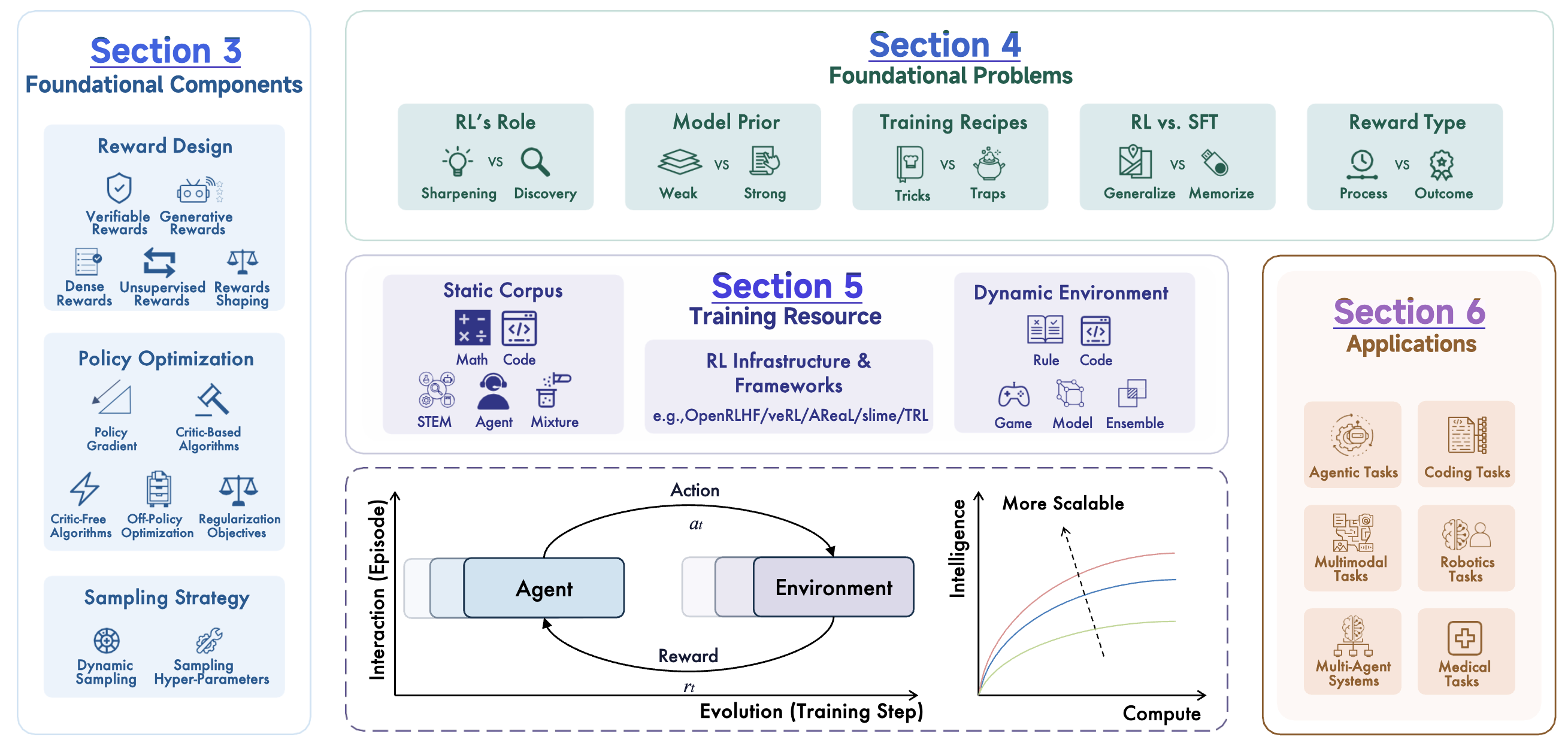 A Survey of Reinforcement Learning for Large Reasoning ModelsKaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jian, Yuchen Fan, +28 more authors , Biqing Qi, Ning Ding, and Bowen Zhou Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jian, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Huayu Chen, Xiaoye Qu, Yafu Li, Weize Chen, Zhenzhao Yuan, Junqi Gao, Dong Li, Ganqu Cui Zhiyuan Ma, Zhiyuan Liu, Biqing Qi, Ning Ding, and Bowen ZhouPreprint
A Survey of Reinforcement Learning for Large Reasoning ModelsKaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jian, Yuchen Fan, +28 more authors , Biqing Qi, Ning Ding, and Bowen Zhou Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jian, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Huayu Chen, Xiaoye Qu, Yafu Li, Weize Chen, Zhenzhao Yuan, Junqi Gao, Dong Li, Ganqu Cui Zhiyuan Ma, Zhiyuan Liu, Biqing Qi, Ning Ding, and Bowen ZhouPreprintIn this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models.
@article{preprint:survey-rl, title = {A Survey of Reinforcement Learning for Large Reasoning Models}, bibtex_show = {true}, journal = {Preprint}, preview = {survey-rl.png}, selected = {true}, author = {Zhang, Kaiyan and Zuo, Yuxin and He, Bingxiang and Sun, Youbang and Liu, Runze and Jian, Che and Fan, Yuchen and Tian, Kai and Jia, Guoli and Li, Pengfei and Fu, Yu and Lv, Xingtai and Zhang, Yuchen and Zeng, Sihang and Qu, Shang and Li, Haozhan and Wang, Shijie and Wang, Yuru and Long, Xinwei and Liu, Fangfu and Xu, Xiang and Ma, Jiaze and Zhu, Xuekai and Hua, Ermo and Liu, Yihao and Li, Zonglin and Chen, Huayu and Qu, Xiaoye and Li, Yafu and Chen, Weize and Yuan, Zhenzhao and Gao, Junqi and Li, Dong and Zhiyuan Ma, Ganqu Cui and Liu, Zhiyuan and Qi, Biqing and Ding, Ning* and Zhou, Bowen}, code = {https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs}, pdf = {https://arxiv.org/abs/2509.08827}, year = {2025} }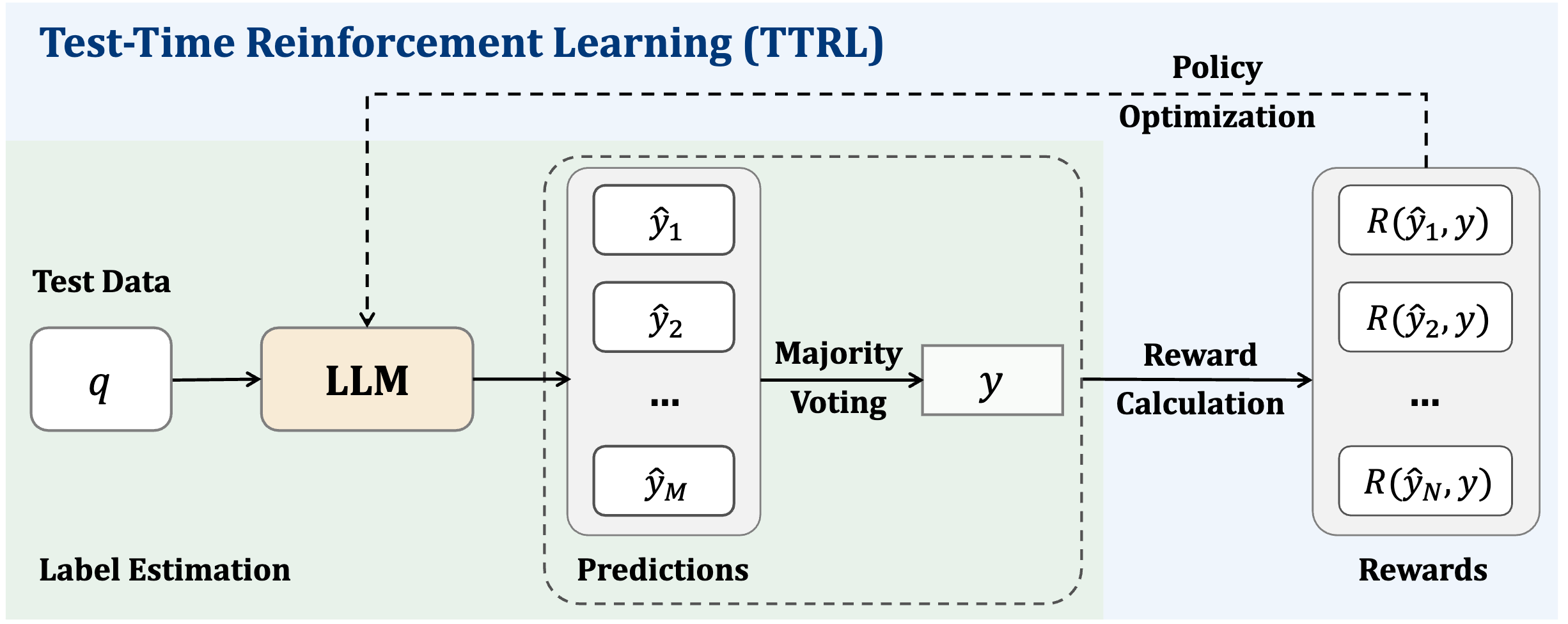 TTRL: Test-time Reinforcement LearningYuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, and Bowen ZhouNeurIPS 2025
TTRL: Test-time Reinforcement LearningYuxin Zuo, Kaiyan Zhang, Shang Qu, Li Sheng, Xuekai Zhu, Biqing Qi, Youbang Sun, Ganqu Cui, Ning Ding, and Bowen ZhouNeurIPS 2025This paper investigates Reinforcement Learning (RL) on data without explicit labels for reasoning tasks in Large Language Models (LLMs). The core challenge of the problem is reward estimation during inference while not having access to ground-truth information. While this setting appears elusive, we find that common practices in Test-Time Scaling (TTS), such as majority voting, yield surprisingly effective rewards suitable for driving RL training. In this work, we introduce Test-Time Reinforcement Learning (TTRL), a novel method for training LLMs using RL on unlabeled data. TTRL enables self-evolution of LLMs by utilizing the priors in the pre-trained models. Our experiments demonstrate that TTRL consistently improves performance across a variety of tasks and models. Notably, TTRL boosts the pass@1 performance of Qwen-2.5-Math-7B by approximately 211% on the AIME 2024 with only unlabeled test data. Furthermore, although TTRL is only supervised by the maj@n metric, TTRL has demonstrated performance to consistently surpass the upper limit of the initial model maj@n, and approach the performance of models trained directly on test data with ground-truth labels. Our experimental findings validate the general effectiveness of TTRL across various tasks and highlight TTRL’s potential for broader tasks and domains.
@article{preprint:ttrl, title = {TTRL: Test-time Reinforcement Learning}, bibtex_show = {true}, selected = {true}, preview = {TTRL.png}, author = {Zuo, Yuxin and Zhang, Kaiyan and Qu, Shang and Sheng, Li and Zhu, Xuekai and Qi, Biqing and Sun, Youbang and Cui, Ganqu and Ding, Ning* and Zhou, Bowen}, journal = {NeurIPS 2025}, code = {https://github.com/PRIME-RL/TTRL}, pdf = {https://arxiv.org/abs/2504.16084}, series = {\newlin NeurIPS 2025}, year = {2025} } Process Reinforcement through Implicit RewardsGanqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, +13 more authors , Maosong Sun, Bowen Zhou, and Ning Ding Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, Zhiyuan Liu, Maosong Sun, Bowen Zhou, and Ning DingPreprint
Process Reinforcement through Implicit RewardsGanqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, +13 more authors , Maosong Sun, Bowen Zhou, and Ning Ding Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, Zhiyuan Liu, Maosong Sun, Bowen Zhou, and Ning DingPreprintDense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME’s effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
@article{preprint:prime, title = {Process Reinforcement through Implicit Rewards}, bibtex_show = {true}, preview = {prime.gif}, selected = {true}, author = {Cui, Ganqu and Yuan, Lifan and Wang, Zefan and Wang, Hanbin and Li, Wendi and He, Bingxiang and Fan, Yuchen and Yu, Tianyu and Xu, Qixin and Chen, Weize and Yuan, Jiarui and Chen, Huayu and Zhang, Kaiyan and Lv, Xingtai and Wang, Shuo and Yao, Yuan and Han, Xu and Peng, Hao and Cheng, Yu and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen and Ding, Ning*}, journal = {Preprint}, pdf = {https://arxiv.org/abs/2502.01456}, series = {\newlin arXiv}, code = {https://github.com/PRIME-RL/PRIME}, huggingface = {https://huggingface.co/PRIME-RL}, year = {Preprint} }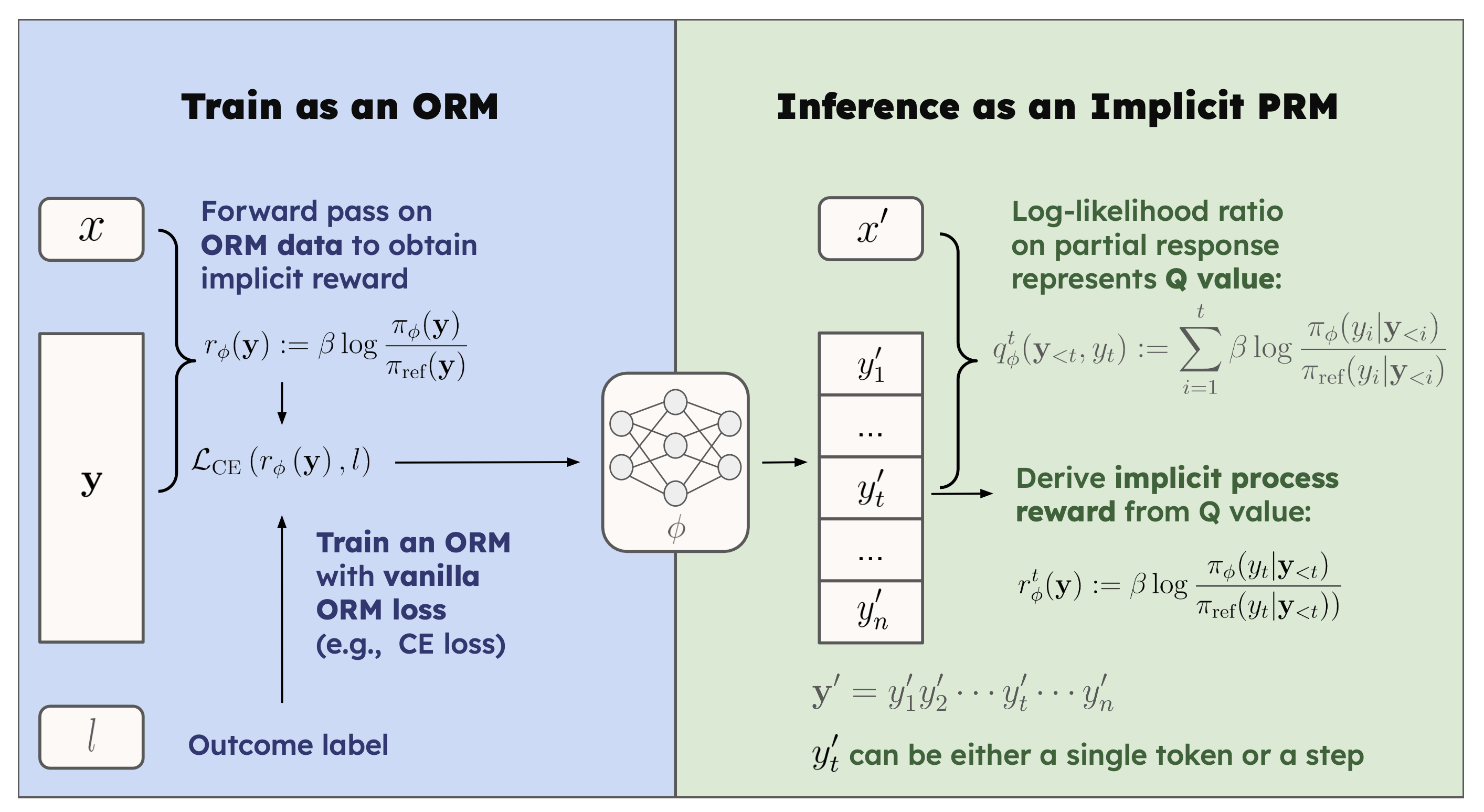 Free Process Rewards without Process LabelsLifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao PengICML 2025
Free Process Rewards without Process LabelsLifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao PengICML 2025Different from its counterpart outcome reward models (ORMs), which evaluate the entire responses, a process reward model (PRM) scores a reasoning trajectory step by step, providing denser and more fine grained rewards. However, training a PRM requires labels annotated at every intermediate step, presenting significant challenges for both manual and automatic data collection. This paper aims to address this challenge. Both theoretically and empirically, we show that an implicit PRM can be obtained at no additional cost, by simply training an ORM on the cheaper response-level labels. The only assumption is to parameterize the outcome reward as the log-likelihood ratios of the policy and reference models, which can be optimized regardless of the specific choice of loss objectives. In experiments, we instantiate our implicit PRMs with various objectives and evaluate their performance on MATH. We show that our implicit PRM outperforms a strong MCTS-based baseline á la Math-Shepherd using less than 1/38 of the training data. Its performance can be further improved with majority voting. We further find that scaling up instructions and responses benefits our implicit PRM, and the latter brings a larger gain. Particularly, we find that our implicit PRM, when instantiated with the cross-entropy (CE) loss, is more data-efficient and can keep improving generation models even when trained with only one response per instruction, the setup that suffers from extreme data scarcity and imbalance. Further, instructions should be relevant to downstream tasks while the diversity of responses does not bring gains. Surprisingly, training on extra Math-Shepherd step labels brings no further improvements to our implicit PRM trained on only outcome data. We hope that our work will encourage a rethinking of PRM training approaches and contribute to making training PRMs more accessible.
@article{preprint:implicitPRM, title = {Free Process Rewards without Process Labels}, bibtex_show = {true}, preview = {implicitPRM.png}, selected = {true}, author = {Yuan, Lifan and Li, Wendi and Chen, Huayu and Cui, Ganqu and Ding, Ning* and Zhang, Kaiyan and Zhou, Bowen and Liu, Zhiyuan and Peng, Hao}, journal = {ICML 2025}, pdf = {https://arxiv.org/abs/2412.01981}, series = {\newlin ICML 2025}, huggingface = {https://huggingface.co/PRIME-RL}, code = {https://github.com/lifan-yuan/ImplicitPRM}, year = {Preprint} } Parameter-efficient Fine-tuning of Large-scale Pre-trained Language ModelsNing Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, +9 more authors , Jie Tang, Juanzi Li, and Maosong Sun Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, Jing Yi, Weilin Zhao, Zhiyuan Liu, Hai-Tao Zheng, Jianfei Chen, Yang Liu, Jie Tang, Juanzi Li, and Maosong SunNature Machine Intelligence
Parameter-efficient Fine-tuning of Large-scale Pre-trained Language ModelsNing Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, +9 more authors , Jie Tang, Juanzi Li, and Maosong Sun Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, Jing Yi, Weilin Zhao, Zhiyuan Liu, Hai-Tao Zheng, Jianfei Chen, Yang Liu, Jie Tang, Juanzi Li, and Maosong SunNature Machine Intelligence
Cover Article of Nature Machine Intelligence’s March Issue
World Artificial Intelligence Conference Youth Outstanding Paper AwardAs pre-trained language models (PLMs) have become the fundamental infrastructure for various NLP tasks and researchers have readily enjoyed themselves in the pretrainingfinetuning paradigm, evidence from emerging research has continuously proven that larger models tend to yield better performance. However, despite the welcome outcome, the process of fine-tuning large-scale PLMs brings prohibitive adaptation costs. In fact, finetuning all the parameters of a colossal model and retaining separate instances for different tasks are practically infeasible. This necessitates a new branch of research focusing on the parameter-efficient adaptation of PLMs. In order to unleash the imagination of the possible advantages of such methods, not limited to parameter efficiency, we coined a new term delta tuning from a morphological point of view to refer to the original “parameter efficient tuning”. In contrast with the standard fine-tuning, delta tuning only fine-tunes a small portion of the model parameters while keeping the rest untouched, largely reducing both the computation and storage costs. Recent studies have demonstrated that a series of delta tuning methods with distinct tuned parameter selection could achieve performance on a par with full-parameter fine-tuning, suggesting a new promising way of stimulating large-scale PLMs. In this paper, we first formally describe the problem of delta tuning and then comprehensively review recent delta tuning approaches. We also propose a unified categorization criterion that divides existing delta tuning methods into three groups: addition-based, specification-based, and reparameterization-based methods. Though initially proposed as an efficient method to steer large models, we believe that some of the fascinating evidence discovered along with delta tuning could help further reveal the mechanisms of PLMs and even deep neural networks. To this end, we discuss the theoretical principles underlying the effectiveness of delta tuning and propose frameworks to interpret delta tuning from the perspective of optimization and optimal control, respectively. Furthermore, we provide a holistic empirical study of representative methods, where results on over 100 NLP tasks demonstrate a comprehensive performance comparison of different approaches. The experimental results also cover the analysis of combinatorial, scaling and transferable properties of delta tuning. To facilitate the research of delta tuning, we are also developing an open-source toolkit, OpenDelta , that enables practitioners to efficiently and flexibly implement delta tuning on PLMs. At last, we discuss a series of real-world applications of delta tuning.
@article{2023:delta, title = {Parameter-efficient Fine-tuning of Large-scale Pre-trained Language Models}, titleb = {Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models}, preview = {NMI.jpg}, bibtex_show = {true}, abbr = {Nat. <br>Mach. <br>Intell.}, code = {https://github.com/thunlp/OpenDelta}, author = {Ding, Ning and Qin, Yujia and Yang, Guang and Wei, Fuchao and Yang, Zonghan and Su, Yusheng and Hu, Shengding and Chen, Yulin and Chan, Chi-Min and Chen, Weize and Yi, Jing and Zhao, Weilin and Liu, Zhiyuan and Zheng, Hai-Tao and Chen, Jianfei and Liu, Yang and Tang, Jie and Li, Juanzi and Sun, Maosong}, journal = {Nature Machine Intelligence}, selected = {true}, arxiv = {2203.06904}, html = {https://www.nature.com/articles/s42256-023-00626-4}, pdf = {https://www.nature.com/articles/s42256-023-00626-4}, award = { <br> <font color="BB0A21"> Cover Article of Nature Machine Intelligence's March Issue </font></strong> <br> <font color="BB0A21"> World Artificial Intelligence Conference Youth Outstanding Paper Award </font> }, series = {\newlin Nature Machine Intelligence}, year = {2023} }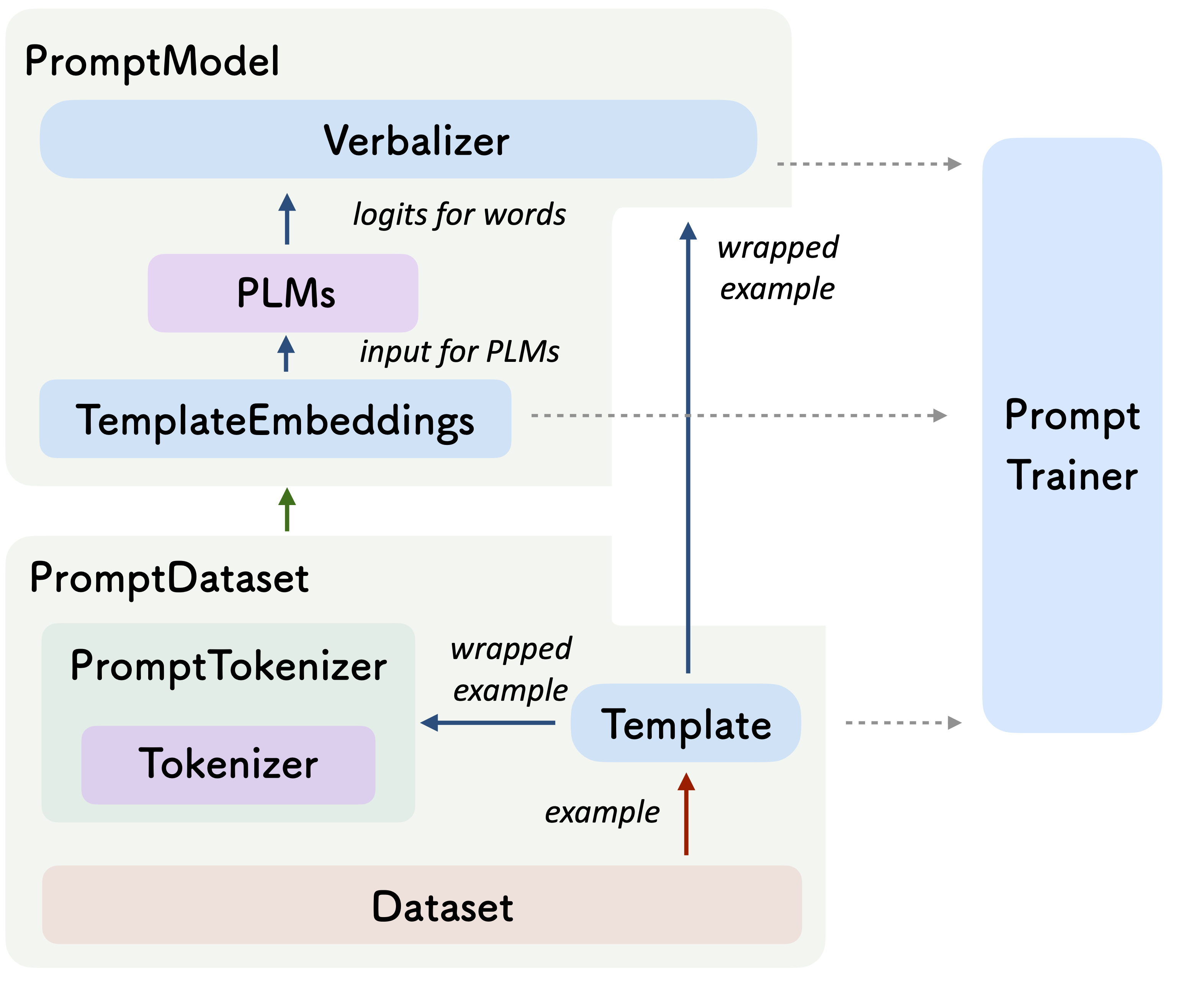 OpenPrompt: An Open-source Framework for Prompt-learningNing Ding, Shengding Hu, Weilin Zhao, Yulin Chen, Zhiyuan Liu, Hai-Tao Zheng, and Maosong SunACL System Demonstration 2022
OpenPrompt: An Open-source Framework for Prompt-learningNing Ding, Shengding Hu, Weilin Zhao, Yulin Chen, Zhiyuan Liu, Hai-Tao Zheng, and Maosong SunACL System Demonstration 2022
 Best Demo Paper Award
Best Demo Paper Award
Prompt-learning has become a new paradigm in modern natural language processing, which directly adapts pre-trained language models (PLMs) to cloze-style prediction, autoregressive modeling, or sequence to sequence generation, resulting in promising performances on various tasks. However, no standard implementation framework of prompt-learning is proposed yet, and most existing prompt-learning codebases, often unregulated, only provide limited implementations for specific scenarios. Since there are many details such as templating strategy, initializing strategy, and verbalizing strategy, etc. need to be considered in prompt-learning, practitioners face impediments to quickly adapting the desired prompt learning methods to their applications. In this paper, we present OpenPrompt, a unified easy-to-use toolkit to conduct prompt-learning over PLMs. OpenPrompt is a research-friendly framework that is equipped with efficiency, modularity, and extendibility, and its combinability allows the freedom to combine different PLMs, task formats, and prompting modules in a unified paradigm. Users could expediently deploy prompt-learning frameworks and evaluate the generalization of them on different NLP tasks without constraints.
@inproceedings{ding2021openprompt, preview = {op.png}, bibtex_show = {true}, title = { OpenPrompt: An Open-source Framework for Prompt-learning}, author = {Ding, Ning and Hu, Shengding and Zhao, Weilin and Chen, Yulin and Liu, Zhiyuan and Zheng, Hai-Tao and Sun, Maosong}, year = {2022}, selected = {true}, booktitle = {ACL System Demonstration}, series = {\newlin ACL System Demonstration}, html = {https://arxiv.org/abs/2111.01998}, pdf = {https://arxiv.org/pdf/2111.01998.pdf}, code = {https://github.com/thunlp/OpenPrompt}, award = { <br> <img src="/assets/img/award.png" width="15px"> <font color="BB0A21"> Best Demo Paper Award </font>} } Enhancing Chat Language Models by Scaling High-quality Instructional ConversationsNing Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen ZhouEMNLP 2023
Enhancing Chat Language Models by Scaling High-quality Instructional ConversationsNing Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen ZhouEMNLP 2023
The Ultra series solutions also contain other works like UltraFeedback (ICML 2024) , UltraInteract (ICLR 2024) , UltraMedical (NeurIPS 2024) , etc.Fine-tuning on instruction data has been widely validated as an effective practice for implementing chat language models like ChatGPT. Scaling the diversity and quality of such data, although straightforward, stands a great chance of leading to improved performance. This paper aims to improve the upper bound of open-source models further. We first provide a systematically designed, diverse, informative, large-scale dataset of instructional conversations, UltraChat, which does not involve human queries. Our objective is to capture the breadth of interactions that a human might have with an AI assistant and employs a comprehensive framework to generate multi-turn conversation iteratively. UltraChat contains 1.5 million high-quality multi-turn dialogues and covers a wide range of topics and instructions. Our statistical analysis of UltraChat reveals its superiority in various key metrics, including scale, average length, diversity, coherence, etc., solidifying its position as a leading open-source dataset. Building upon UltraChat, we fine-tune a LLaMA model to create a powerful conversational model, UltraLLaMA. Our evaluations indicate that UltraLLaMA consistently outperforms other open-source models, including Vicuna, the previously recognized state-of-the-art open-source model.
@inproceedings{preprint:ultra, title = {Enhancing Chat Language Models by Scaling High-quality Instructional Conversations}, preview = {ultra_logo.png}, bibtex_show = {true}, author = {Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen}, booktitle = {EMNLP}, selected = {true}, pdf = {https://arxiv.org/abs/2305.14233}, code = {https://github.com/thunlp/UltraChat}, series = {\newlin EMNLP}, award = { <br> The Ultra series solutions also contain other works like <a href="https://arxiv.org/abs/2310.01377">UltraFeedback (ICML 2024)</a> </font></strong> , <a href="https://arxiv.org/abs/2404.02078">UltraInteract (ICLR 2024)</a> </font></strong> , <a href="https://arxiv.org/abs/2406.03949">UltraMedical (NeurIPS 2024)</a> </font></strong>, etc. </strong>}, year = {2023} }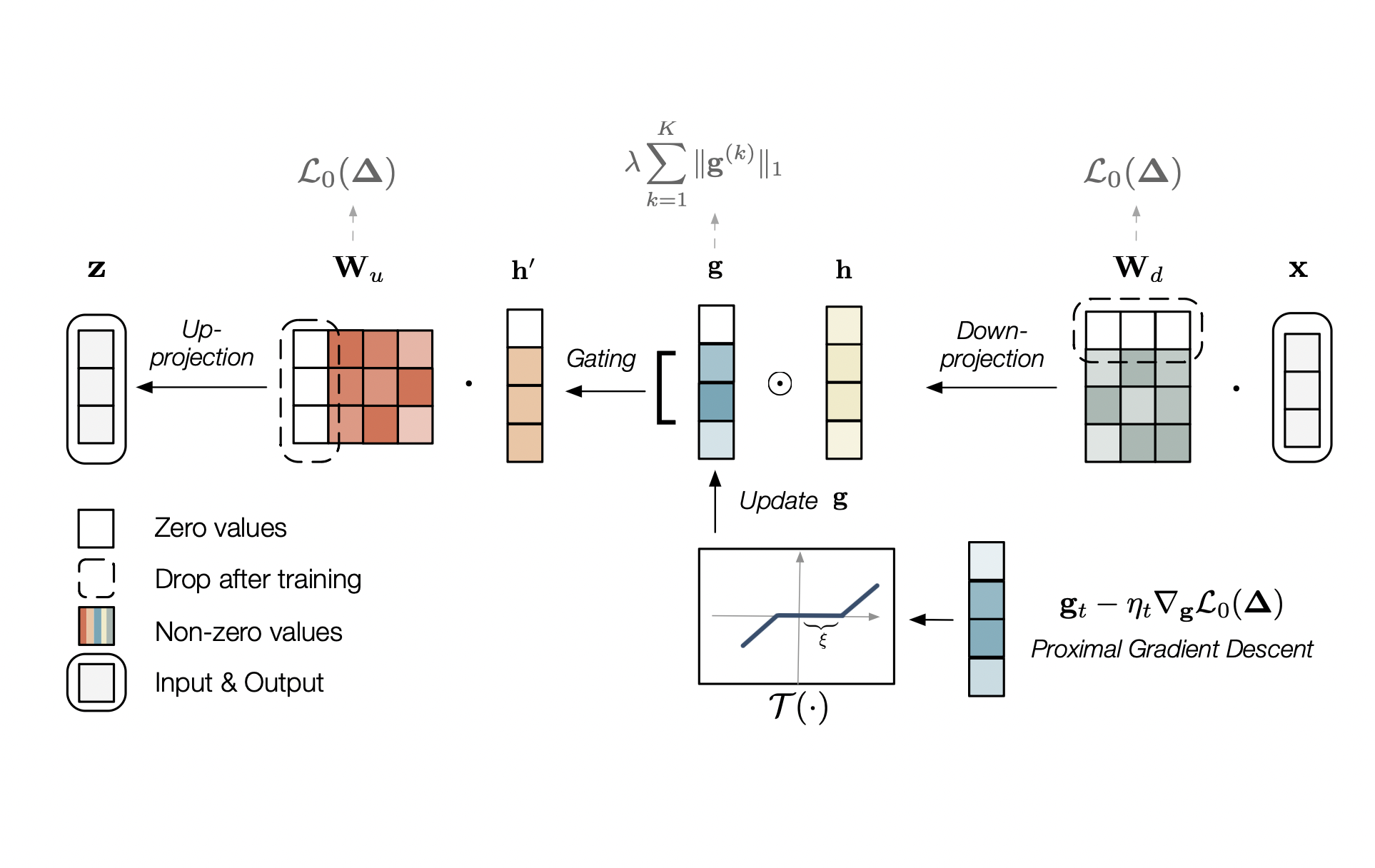 Sparse Low-rank Adaptation of Pre-trained Language ModelsNing Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen ZhouEMNLP 2023
Sparse Low-rank Adaptation of Pre-trained Language ModelsNing Ding, Yulin Chen, Bokai Xu, Yujia Qin, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen ZhouEMNLP 2023Fine-tuning pre-trained large language models in a parameter-efficient manner is widely studied for its effectiveness and efficiency. The popular method of low-rank adaptation (LoRA) offers a notable approach, hypothesizing that the adaptation process is intrinsically low-dimensional. Although LoRA has demonstrated commendable performance, it is implemented with a fixed and unalterable intrinsic rank that might not always be the ideal choice. Recognizing the need for more flexible adaptation, we extend the methodology of LoRA to an innovative approach we call sparse low-rank adaptation (SoRA) that enables dynamic adjustments to the intrinsic rank during the adaptation process. We achieve this through the incorporation of a gate unit optimized with proximal gradient method in the training stage, controlling the cardinality of rank under the sparsity of the gate. In the subsequent inference stage, we eliminate the parameter blocks corresponding to the zeroed-out ranks, to reduce each SoRA module back to a concise yet rank-optimal LoRA. Our approach strengthens the representation power of LoRA by initializing it with a higher rank, while efficiently taming a temporarily increased number of parameters via updating in a sparse way. We further introduce a sparsifying scheduler for SoRA, aiming to examine the impact of the number of non-zero parameters on the model’s memorization and generalization. Our experimental results demonstrate that SoRA can outperform other baselines even with 70% retained parameters and 70% training time.
@inproceedings{preprint:sora, title = {Sparse Low-rank Adaptation of Pre-trained Language Models}, preview = {sora.png}, selected = {true}, bibtex_show = {true}, author = {Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen}, pdf = {https://arxiv.org/abs/2311.11696}, booktitle = {EMNLP}, series = {\newlin EMNLP}, code = {https://github.com/TsinghuaC3I/SoRA}, year = {2023} }
Awards
- Yunfan Award of WAIC, 2024.
- Young Elite Scientists Sponsorship Program by CAST, 2023.
- World Artificial Intelligence Conference Youth Outstanding Paper Award, 2023.
- Shuimu Tsinghua Scholar Program, 2023.
- Zhang Keqian Scholar Program, 2023.
- Outstanding Doctoral Dissertation of Tsinghua University, 2023.
- Outstanding Graduate of DCST, Tsinghua University, 2023.
- ACL Best System Demonstration Paper Award, 2022.
- Baidu Ph.D Fellowship (10 recipients worldwide), 2021.
- National Scholarship for Ph.D student, 2021.
- National Scholarship for Ph.D student, 2020.
- Tsingfeng Scholarship, Tsinghua University, 2019.
- CACS Scholarship, 2019.
- Excellent Graduate, 2018.
- National Scholarship for undergraduate student, 2018.
- First-class Academic Scholarship, 2017.
- First-class Academic Scholarship, 2016.
Service
- Nature Machine Intelligence
- Neural Networks
- NeurIPS 2020~2024
- ICML 2021~2024
- ACL 2020~2024
- EMNLP 2020~2024
- COLING 2020, 2022
- AAAI 2020~2024
- IJCAI 2020